
In today’s data-driven world, efficient data storage and processing are crucial. One of the best tools for this job is the Parquet file format. But what exactly is a Parquet file, and why should you care about it? Let’s break it down in simple terms and explore how it can save you time and money.
What is a Parquet File?
Imagine you have a giant spreadsheet with millions of rows and columns of data—like a huge list of customer information. Traditional formats store this data row by row. But Parquet files do things a bit differently. They store data in a columnar storage format, meaning data is organized column by column rather than row by row.

This columnar storage is beneficial because if you only need to look at the “Name” column, Parquet files can quickly fetch just that column without dealing with the other columns. This results in much faster data retrieval and analysis.
Uses of Parquet Files
1. Big Data Processing
Parquet files are essential in big data ecosystems. They are used in powerful tools like Apache Spark and Hadoop for processing large volumes of data efficiently. Think of Parquet files as the heavy-duty trucks that transport large amounts of data quickly.
2. Data Warehousing
When businesses need to store and organize vast amounts of data, such as sales records, customer details, or inventory logs, Parquet files are an excellent choice. They enable efficient data warehousing, making data access and analysis easier.
3. Data Lakes
In a data lake, where diverse data types are stored, Parquet files are a perfect fit. They handle different types of data efficiently, providing a scalable solution for large-scale data storage.
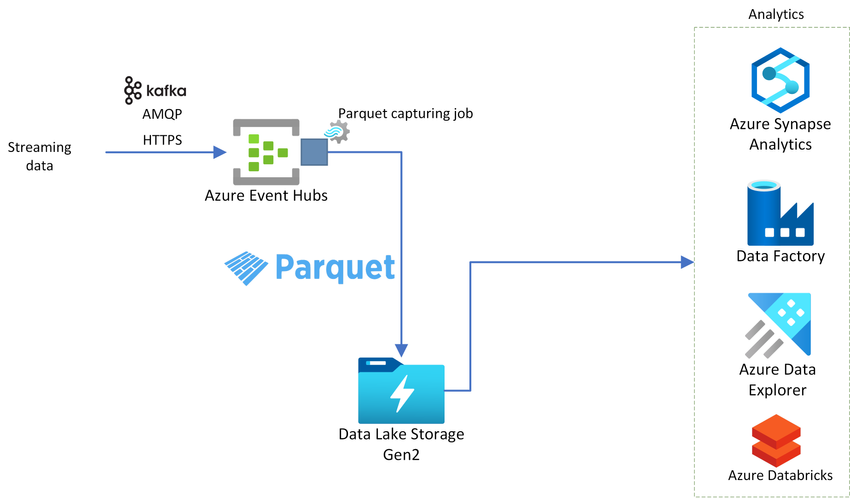
Why Do We Need Parquet Files?
1. Better Performance
Parquet files store data in a columnar format, enhancing data retrieval speed and efficiency. For example, if you need to find the “Email” column in a dataset, Parquet files can quickly access it without sifting through unnecessary data.
2. Saves Space
Compression techniques used in Parquet files reduce the storage space required. It’s like packing your clothes in vacuum-sealed bags to save room in your suitcase.
3. Adapts to Changes
If your data structure changes—like adding new columns or updating existing ones—Parquet files manage these changes smoothly without disrupting access. It’s like having a flexible bookshelf that adjusts to fit more books as your collection grows.
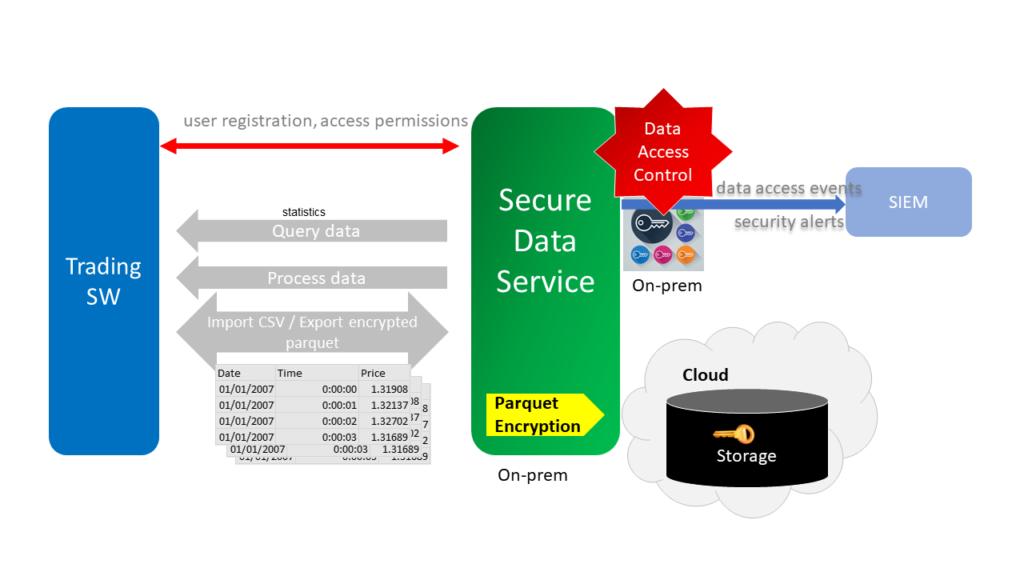
How Parquet Files Help Save Money
1. Reduces Storage Costs
With compression and efficient storage, Parquet files can cut down on storage costs. Some organizations have saved up to 80% on their storage bills by switching to Parquet files.
2. Cuts Down Processing Costs
Faster data retrieval leads to lower processing costs. Imagine saving money by spending less time waiting for data to load and process.
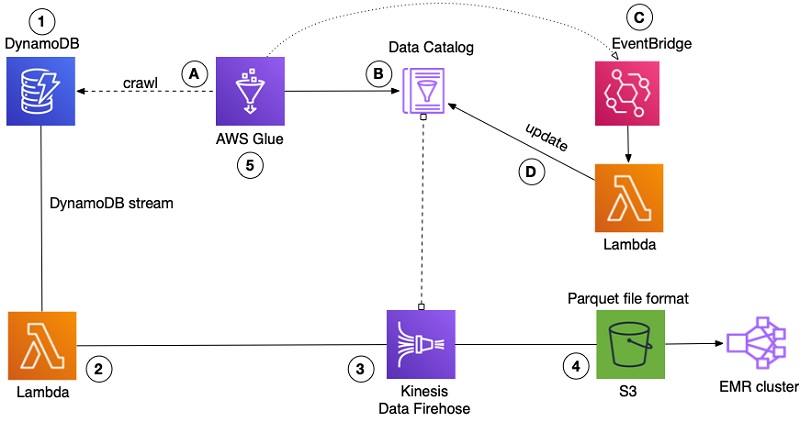
How AWS Uses Parquet Files to Tackle Data Challenges
1. Amazon Redshift Spectrum
AWS Redshift Spectrum allows you to query data stored in Parquet files directly from Amazon S3, enabling insights without data movement.
2. AWS Glue
AWS Glue utilizes Parquet files for efficient data transformation tasks. It’s like having a highly efficient assistant that handles large datasets quickly.
3. AWS Athena
AWS Athena lets you query Parquet files without setting up servers, offering a powerful search tool for quick data insights.
Conclusion
In summary, Parquet files are a powerful tool for efficient data storage and processing. They offer faster data access, cost savings, and adaptability to changing data needs. To optimize your data management, consider using Parquet files. For more information and tools related to Parquet files, visit our resources at ParquetReader.in. Happy data managing!